
360AI推出DiT架构下"省钱版"ControlNet, 参数量骤减85%性能达到SOTA!
360AI推出DiT架构下"省钱版"ControlNet, 参数量骤减85%性能达到SOTA!现有的可控Diffusion Transformer方法,虽然在推进文本到图像和视频生成方面取得了显著进展,但也带来了大量的参数和计算开销。
来自主题: AI技术研报
8218 点击 2025-03-03 10:06
 搜索
搜索
现有的可控Diffusion Transformer方法,虽然在推进文本到图像和视频生成方面取得了显著进展,但也带来了大量的参数和计算开销。
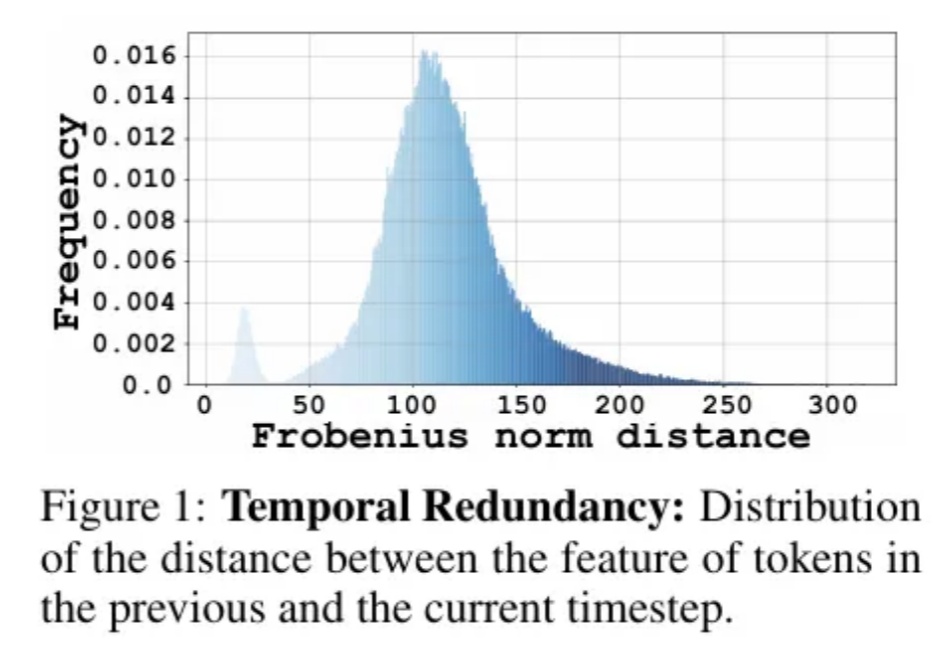
Diffusion Transformer模型模型通过token粒度的缓存方法,实现了图像和视频生成模型上无需训练的两倍以上的加速。

这位曾用代码构建童话世界的工程师,被困在了由 AI 工具引发的一场噩梦里。

进入到 2025 年,视频生成(尤其是基于扩散模型)领域还在不断地「推陈出新」,各种文生视频、图生视频模型展现出了酷炫的效果。其中,长视频生成一直是现有视频扩散的痛点。

在过去的两年里,城市场景生成技术迎来了飞速发展,一个全新的概念 ——世界模型(World Model)也随之崛起。当前的世界模型大多依赖 Video Diffusion Models(视频扩散模型)强大的生成能力,在城市场景合成方面取得了令人瞩目的突破。然而,这些方法始终面临一个关键挑战:如何在视频生成过程中保持多视角一致性?
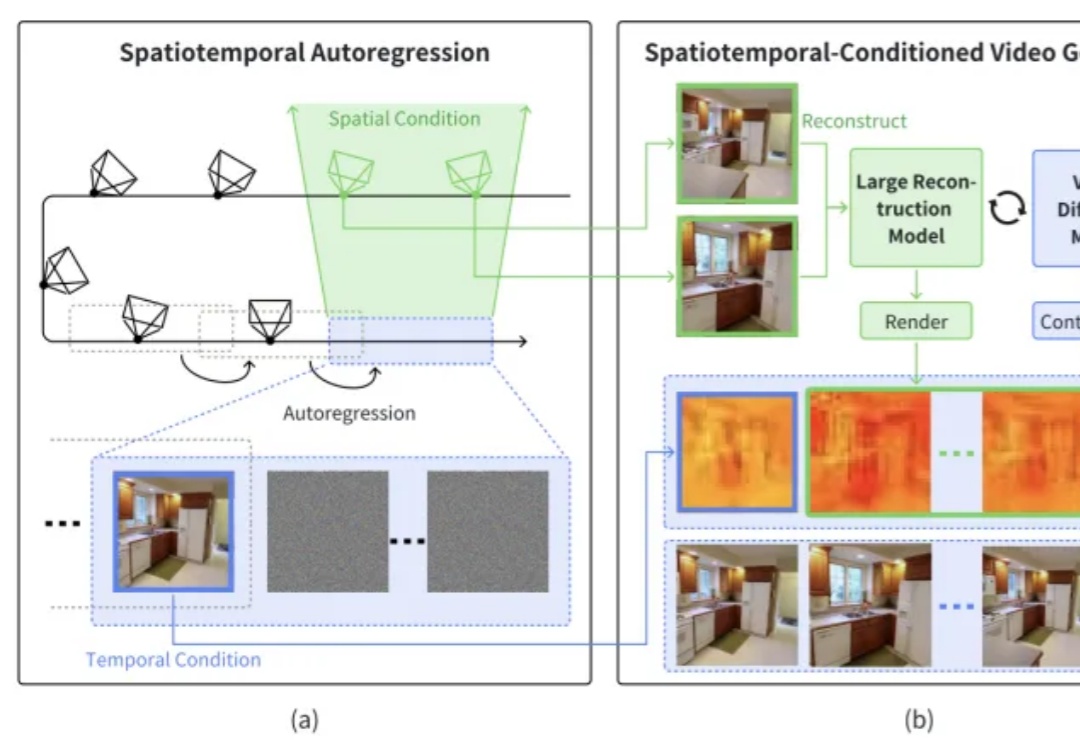
本文介绍了一篇由浙江大学章国锋教授和商汤科技研究团队联合撰写的论文《StarGen: A Spatiotemporal Autoregression Framework with Video Diffusion Model for Scalable and Controllable Scene Generation》。
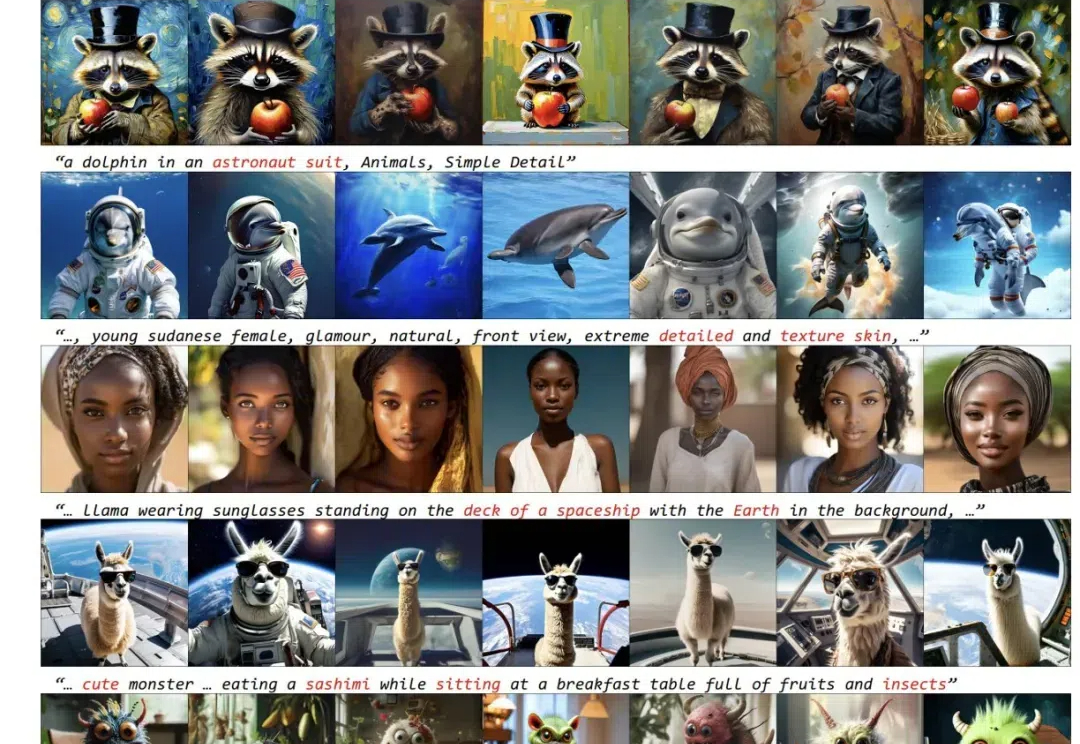
近些年来,以 Stable Diffusion 为代表的扩散模型为文生图(T2I)任务树立了新的标准,PixArt,LUMINA,Hunyuan-DiT 以及 Sana 等工作进一步提高了图像生成的质量和效率。然而,目前的这些文生图(T2I)扩散模型受限于模型尺寸和运行时间,仍然很难直接部署到移动设备上。
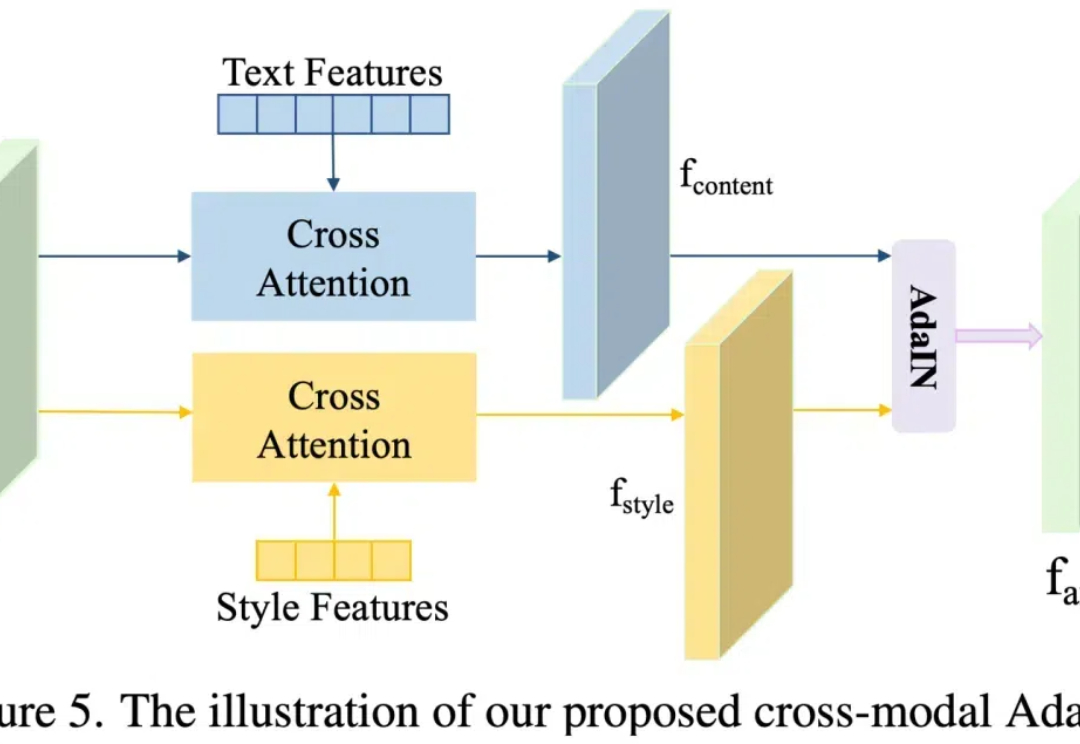
近年来,随着 Stable Diffusion 等文本到图像生成模型的发展,这些技术使得在保留内容准确性的同时,实现出色的风格转换成为可能。这项技术在数字绘画、广告和游戏设计等领域具有重要的应用价值。

具备原生中文理解能力,还兼容Stable Diffusion生态。 最新模型结构Bridge Diffusion Model来了。 与Dreambooth模型结合,它生成的穿中式婚礼礼服的歪国明星长这样。
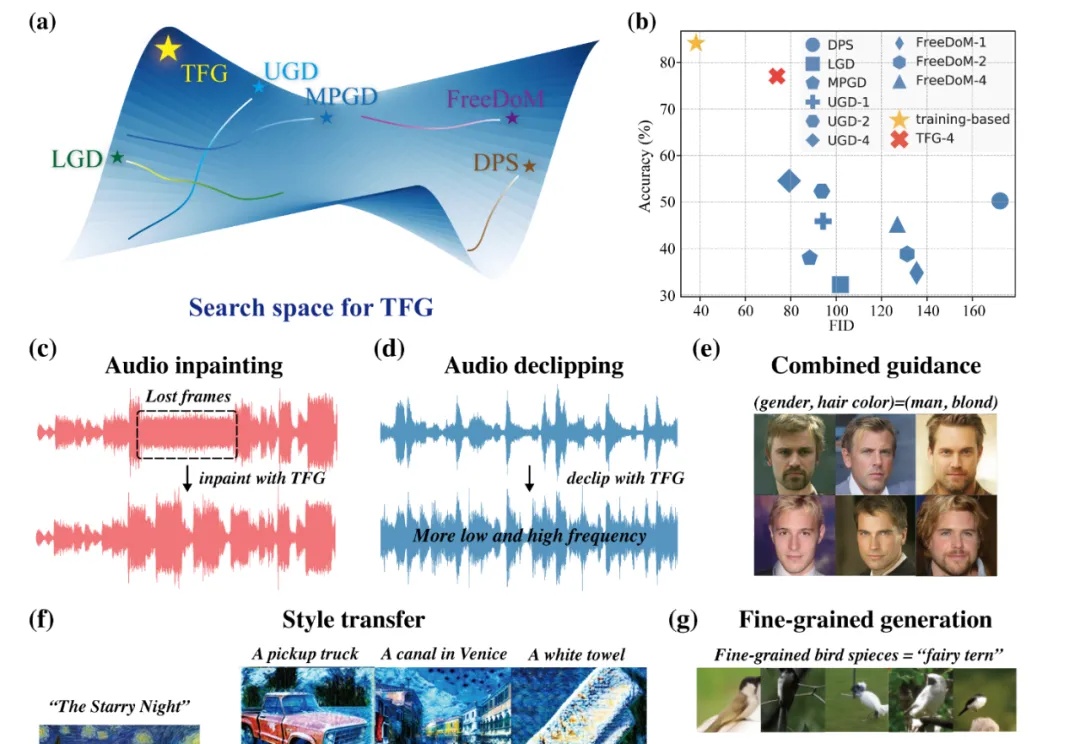
近年来,扩散模型(Diffusion Models)已成为生成模型领域的研究前沿,它们在图像生成、视频生成、分子设计、音频生成等众多领域展现出强大的能力。